前言 在前些年,笔者主要使用的是python语言进行数据的分析工作。在后面到研二期间进行生物数据的处理时,发现R语言在转录组分析或代谢组学分析的场景应用更加广泛,基于以上需求,遂开始对R语言的语法与数据结构进行学习并整理。
R包的安装 常用模块的安装在R语言中是使用以下命令进行安装
R包的更新
安装与应用的实例
1 2 3 4 5 if (!requireNamespace("BiocManager" , quietly = TRUE)) install.packages("BiocManager" ) BiocManager::install("DESeq2" ) library(DESeq2)
在这里是先通过安装BiocManager,再通过BiocManager安装DESeq2的模块,而后引用DESeq2这个包
R包的使用 引用
展示使用文档
1 2 3 help (package="xxx" )help (package="ggplot2" )
移除使用中的包
1 2 3 detach("package:xxx") # 实例 detach("package:ggplot2")
变量 R语言的变量赋值是用箭头表示,也可以用等号表示,但不常用
注意,变量名的第一个字符不能取为数字
数据结构 数据类型 数值型:123、123.123等 字符串型:”string” 逻辑型:TRUE、FALSE 日期型等 数据结构 向量 用函数c来创建向量
1 2 3 x <- c(1, 2, 3, 4, 5) # 数值型 y <- c("one", "two", "three") # 字符串型 z <- c(TRUE, FALSE, T, F) # 逻辑型
数组的冒号功能类似于python中的range()函数,但区别是python中的range(1:5)只会输出1 2 3 4,不囊括5,而R语言是全部囊括
使用seq去生成向量
1 2 3 4 > seq(from=1, to=5) [1] 1 2 3 4 5 > seq(from=1, to=6,by=2) # 间隔为2 [1] 1 3 5
使用rep去生成含有重复元素的向量
1 2 > rep(2, 5) [1] 2 2 2 2 2
注,向量的元素必须是同一个类型,不能混合
查看数组元素类型
向量索引 1 2 3 4 5 6 7 8 9 10 11 12 13 14 > x <- c(1 :100 ) > x [1 ] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 [19 ] 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 [37 ] 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 [55 ] 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 [73 ] 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 [91 ] 91 92 93 94 95 96 97 98 99 100 > length(x) [1 ] 100 > x[1 ] [1 ] 1 > x[55 ] [1 ] 55
使用索引功能的语法与python相似,但不是从0开始,在这里索引到1是直接x[1],而非像python那样x[0]
1 2 3 4 5 6 7 > x[-19 ] [1 ] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 20 [20 ] 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 [39 ] 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 [58 ] 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 [77 ] 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 [96 ] 97 98 99 100
使用负索引输出除19外所有的元素
1 2 3 4 > x[c(4 :18 )] [1 ] 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 > x[c(1 ,2 ,55 ,18 )] [1 ] 1 2 55 18
综合使用向量进行索引操作
1 2 3 4 5 > y <- c(1 :5 ) > y [1 ] 1 2 3 4 5 > y[c(T,F,F,T,T)] [1 ] 1 4 5
使用逻辑型进行索引输出,TRUE输出,FALSE则不输出
1 2 3 4 5 6 7 8 > y[c(T)] [1 ] 1 2 3 4 5 > y[c(F)] integer(0 ) > y[c(T,F)] [1 ] 1 3 5 > y[c(T,F,F)] [1 ] 1 4
使用逻辑型进行索引的进阶使用
1 2 3 4 5 6 7 > z <- c("one" , "two" , "three" , "four" ) > z [1 ] "one" "two" "three" "four" > "one" %in % z [1 ] TRUE > z[z %in % c("one" , "two" )] [1 ] "one" "two"
含字符串的向量的索引使用方法,”one” %in% z 表示one字符串是否在z里面,在就输出TRUE。根据该特性,可用于选中数组中含有的元素
1 2 3 4 5 6 > y [1 ] 1 2 3 4 5 > names(y) <- c("one" , "two" , "three" , "four" , "five" ) > y one two three four five 1 2 3 4 5
使用name() 给数组的元素进行命名。这个操作让我想起了python中字典这个数据结构
1 2 3 4 5 6 > y["two" ] two 2 > y["five" ] five 5
当然,可以通过命名的名称作为索引来输出y的值
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 > x [1 ] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 [19 ] 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 [37 ] 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 [55 ] 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 [73 ] 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 [91 ] 91 92 93 94 95 96 97 98 99 100 > x[101 ] <- 101 > x [1 ] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 [19 ] 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 [37 ] 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 [55 ] 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 [73 ] 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 [91 ] 91 92 93 94 95 96 97 98 99 100 101 > x[c(102 :110 )] <- c(102 :110 ) > x [1 ] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 [19 ] 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 [37 ] 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 [55 ] 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 [73 ] 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 [91 ] 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 [109 ] 109 110
数组添加元素的方式也是简单暴力
1 2 3 4 5 6 7 8 > append(x, values = 99 , after = 3 ) [1 ] 1 2 3 99 4 5 6 7 8 9 10 11 12 13 14 15 16 17 [19 ] 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 [37 ] 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 [55 ] 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 [73 ] 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 [91 ] 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 [109 ] 108 109 110
使用append()函数,在数组的第三个索引后,添加99的数值
向量运算 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 > x [1 ] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 [19 ] 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 [37 ] 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 [55 ] 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 [73 ] 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 [91 ] 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 [109 ] 109 110 > x+1 [1 ] 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 [19 ] 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 [37 ] 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 [55 ] 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 [73 ] 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 [91 ] 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 [109 ] 110 111 > x-3 [1 ] -2 -1 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 [19 ] 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 [37 ] 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 [55 ] 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 [73 ] 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 [91 ] 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 [109 ] 106 107
向量的加减法是有着对每个元素进行加减的操作
1 2 3 4 5 6 7 8 9 10 11 > x>50 [1 ] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE [13 ] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE [25 ] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE [37 ] FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE FALSE [49 ] FALSE FALSE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE [61 ] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE [73 ] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE [85 ] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE [97 ] TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE [109 ] TRUE TRUE
向量也可以以逻辑型进行输出
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 > x <- c(-5 :5 ) > x [1 ] -5 -4 -3 -2 -1 0 1 2 3 4 5 > abs (x) [1 ] 5 4 3 2 1 0 1 2 3 4 5 > sqrt(x) [1 ] NaN NaN NaN NaN NaN 0.000000 1.000000 1.414214 [9 ] 1.732051 2.000000 2.236068 Warning message: In sqrt(x) : NaNs produced > sqrt(25 ) [1 ] 5 > log(16 , base = 2 ) [1 ] 4 > log10(10 ) [1 ] 1 > exp(x) [1 ] 6.737947e-03 1.831564e-02 4.978707e-02 1.353353e-01 3.678794e-01 [6 ] 1.000000e+00 2.718282e+00 7.389056e+00 2.008554e+01 5.459815e+01 [11 ] 1.484132e+02
这里展示了r语言中常用的函数,部分函数与python一致。此外还有取整函数trunc(),四舍五入函数round(),还有sin(x),cos(x)等,在此不作额外介绍。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 > vec <- 1 :100 > vec [1 ] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 [19 ] 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 [37 ] 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 [55 ] 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 [73 ] 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 [91 ] 91 92 93 94 95 96 97 98 99 100 > sum (vec) [1 ] 5050 > max (vec) [1 ] 100 > min (vec) [1 ] 1 > range (vec) [1 ] 1 100 > mean(vec) [1 ] 50.5 > var(vec) [1 ] 841.6667 > median(vec) [1 ] 50.5
矩阵 1 2 3 4 5 6 7 > m <- matrix(1 :20 , 4 , 5 ) > m [,1 ] [,2 ] [,3 ] [,4 ] [,5 ] [1 ,] 1 5 9 13 17 [2 ,] 2 6 10 14 18 [3 ,] 3 7 11 15 19 [4 ,] 4 8 12 16 20
创建矩阵使用matrix函数,图例中创建一个4行5列的矩阵。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 > m <- matrix(1 :20 , 4 ) > m [,1 ] [,2 ] [,3 ] [,4 ] [,5 ] [1 ,] 1 5 9 13 17 [2 ,] 2 6 10 14 18 [3 ,] 3 7 11 15 19 [4 ,] 4 8 12 16 20 > m <- matrix(1 :20 , 4 , byrow=T) > m [,1 ] [,2 ] [,3 ] [,4 ] [,5 ] [1 ,] 1 2 3 4 5 [2 ,] 6 7 8 9 10 [3 ,] 11 12 13 14 15 [4 ,] 16 17 18 19 20 > m <- matrix(1 :20 , 4 , byrow=F) > m [,1 ] [,2 ] [,3 ] [,4 ] [,5 ] [1 ,] 1 5 9 13 17 [2 ,] 2 6 10 14 18 [3 ,] 3 7 11 15 19 [4 ,] 4 8 12 16 20
可使用byrow进行行列排列的选择,TRUE是按行排列,FALSE是按列进行排列
1 2 3 4 5 6 7 8 9 > rnames <- c("R1" , "R2" , "R3" , "R4" ) > cnames <- c("C1" , "C2" , "C3" , "C4" , "C5" ) > dimnames(m) <- list (rnames, cnames) > m C1 C2 C3 C4 C5 R1 1 5 9 13 17 R2 2 6 10 14 18 R3 3 7 11 15 19 R4 4 8 12 16 20
可通过dimnames()函数,对矩阵进行命名,后续可通过名字,提取元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 > x [1 ] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 > dim(x) <- c(2 ,2 ,5 ) > x , , 1 [,1 ] [,2 ] [1 ,] 1 3 [2 ,] 2 4 , , 2 [,1 ] [,2 ] [1 ,] 5 7 [2 ,] 6 8 , , 3 [,1 ] [,2 ] [1 ,] 9 11 [2 ,] 10 12 , , 4 [,1 ] [,2 ] [1 ,] 13 15 [2 ,] 14 16 , , 5 [,1 ] [,2 ] [1 ,] 17 19 [2 ,] 18 20 >
使用dim()函数将矩阵转换为三维数组,这个操作有点像pytorch里面的reshape()函数,当然reshape()函数和dim()用法是不一样的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 > dim1 <- c("A1" , "A2" ) > dim2 <- c("B1" , "B2" , "B3" ) > dim3 <- c("C1" , "C2" , "C3" , "C4" ) > z <- array(1 :24 , c(2 , 3 , 4 ), list (dim1, dim2, dim3)) > z , , C1 B1 B2 B3 A1 1 3 5 A2 2 4 6 , , C2 B1 B2 B3 A1 7 9 11 A2 8 10 12 , , C3 B1 B2 B3 A1 13 15 17 A2 14 16 18 , , C4 B1 B2 B3 A1 19 21 23 A2 20 22 24 >
这里展示了使用array()函数创建矩阵并命名的操作。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 > m <- matrix(1 :20 ,4 ,5 ,byrow=T) > m [,1 ] [,2 ] [,3 ] [,4 ] [,5 ] [1 ,] 1 2 3 4 5 [2 ,] 6 7 8 9 10 [3 ,] 11 12 13 14 15 [4 ,] 16 17 18 19 20 > m[1 ,2 ] [1 ] 2 > m[1 ,] [1 ] 1 2 3 4 5 > m[,2 ] [1 ] 2 7 12 17 > m[-1 ,2 ] [1 ] 7 12 17
这里展示了怎么通过索引访问矩阵的元素的方式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 > m [,1 ] [,2 ] [,3 ] [,4 ] [,5 ] [1 ,] 1 2 3 4 5 [2 ,] 6 7 8 9 10 [3 ,] 11 12 13 14 15 [4 ,] 16 17 18 19 20 > m+1 [,1 ] [,2 ] [,3 ] [,4 ] [,5 ] [1 ,] 2 3 4 5 6 [2 ,] 7 8 9 10 11 [3 ,] 12 13 14 15 16 [4 ,] 17 18 19 20 21 > m**2 [,1 ] [,2 ] [,3 ] [,4 ] [,5 ] [1 ,] 1 4 9 16 25 [2 ,] 36 49 64 81 100 [3 ,] 121 144 169 196 225 [4 ,] 256 289 324 361 400 >
这里展示了矩阵的计算
1 2 3 4 5 6 7 8 > colSums(m) [1 ] 34 38 42 46 50 > rowSums(m) [1 ] 15 40 65 90 > colMeans(m) [1 ] 8.5 9.5 10.5 11.5 12.5 > rowMeans(m) [1 ] 3 8 13 18
矩阵也可以计算其行列的sum与mean
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 > n <- matrix(1 :9 , 3 ,3 ) > n [,1 ] [,2 ] [,3 ] [1 ,] 1 4 7 [2 ,] 2 5 8 [3 ,] 3 6 9 > t <- matrix(2 :10 , 3 ,3 ) > t [,1 ] [,2 ] [,3 ] [1 ,] 2 5 8 [2 ,] 3 6 9 [3 ,] 4 7 10 > n * t [,1 ] [,2 ] [,3 ] [1 ,] 2 20 56 [2 ,] 6 30 72 [3 ,] 12 42 90 > n %*% t [,1 ] [,2 ] [,3 ] [1 ,] 42 78 114 [2 ,] 51 96 141 [3 ,] 60 114 168
在这里展示了矩阵的乘法
1 2 3 4 5 6 7 > diag(n) [1 ] 1 5 9 > t(n) [,1 ] [,2 ] [,3 ] [1 ,] 1 2 3 [2 ,] 4 5 6 [3 ,] 7 8 9
这里展示了求矩阵的对角线和矩阵的转置
列表 列表和向量类似,都是一维数据集合
向量只能存储一种数据类型,列表中的对象可以是R中的任何数据结构,甚至是列表本身。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 > a <- 1 :10 > b <- c('1' , '2' , '3' , 'do' ) > c <- c(TRUE,FALSE) > mlist <- list (a, b, c) > mlist [[1 ]] [1 ] 1 2 3 4 5 6 7 8 9 10 [[2 ]] [1 ] "1" "2" "3" "do" [[3 ]] [1 ] TRUE FALSE >
使用list()函数去创建一个列表
1 2 3 4 5 6 7 8 9 10 11 12 > mlist <- list (one=a, two=b, three=c) > mlist $one [1 ] 1 2 3 4 5 6 7 8 9 10 $two [1 ] "1" "2" "3" "do" $three [1 ] TRUE FALSE >
列表也可以取名
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 > mlist[1 ] $one [1 ] 1 2 3 4 5 6 7 8 9 10 > mlist[c(1 :3 )] $one [1 ] 1 2 3 4 5 6 7 8 9 10 $two [1 ] "1" "2" "3" "do" $three [1 ] TRUE FALSE > mlist[c('one' )] $one [1 ] 1 2 3 4 5 6 7 8 9 10 > mlist$one [1 ] 1 2 3 4 5 6 7 8 9 10
列表可以用不同的方式去访问其元素
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 > mlist[[4 ]] <- c(5 :7 ) > mlist $one [1 ] 1 2 3 4 5 6 7 8 9 10 $two [1 ] "1" "2" "3" "do" $three [1 ] TRUE FALSE [[4 ]] [1 ] 5 6 7 > mlist[-1 ] $two [1 ] "1" "2" "3" "do" $three [1 ] TRUE FALSE [[3 ]] [1 ] 5 6 7
这里反映了列表中如何添加与删除元素。同时也可以使用譬如mlist[3] <- NULL来删除列表中的元素
数据框 数据框是一种表格式的数据结构。数据框旨在模拟数据集,与其他统计软件例如SAS或者SPSS中的数据集的概念一致。
数据集通常是由数据构成的一个矩形数组,行表示观测,列表示变量。
数据框实际上是一个列表。列表中的元素是向量,这些向量构成数据框的列,每一列必须具有相同的长度,所以数据框是矩形结构,而且数据框的列必须命名。
数据框最常见的表示方式如图所示,其结构换个说法就像是一个excel的一个表格。
因此对数据框的总结如下:
数据框形状上很像矩阵 数据框是比较规则的列表 矩阵必须是同一数据类型 数据框每一列必须为同一类型,每一行可以不同 数据框的访问与列表一致,在这里不作重复阐述。
因子 因子,在R中名义型变量和有序性变量称为因子,factor。这些分类变量的可能值称为一个水平,level,例如good,better,best,都称为一个level。由这些水平值构成的向量就称为因子。
因子有着非常多的应用
计算频数 独立性检验 相关性检验 方差分析 主成分分析 因子分析 1 2 3 4 > f <- factor(c("r" ,"r" ,"g" ,"b" ,"g" ,"b" ,"b" )) > f [1 ] r r g b g b b Levels: b g r
使用factor()函数定义一个因子,当然该函数同样也可以将向量转换为一个因子
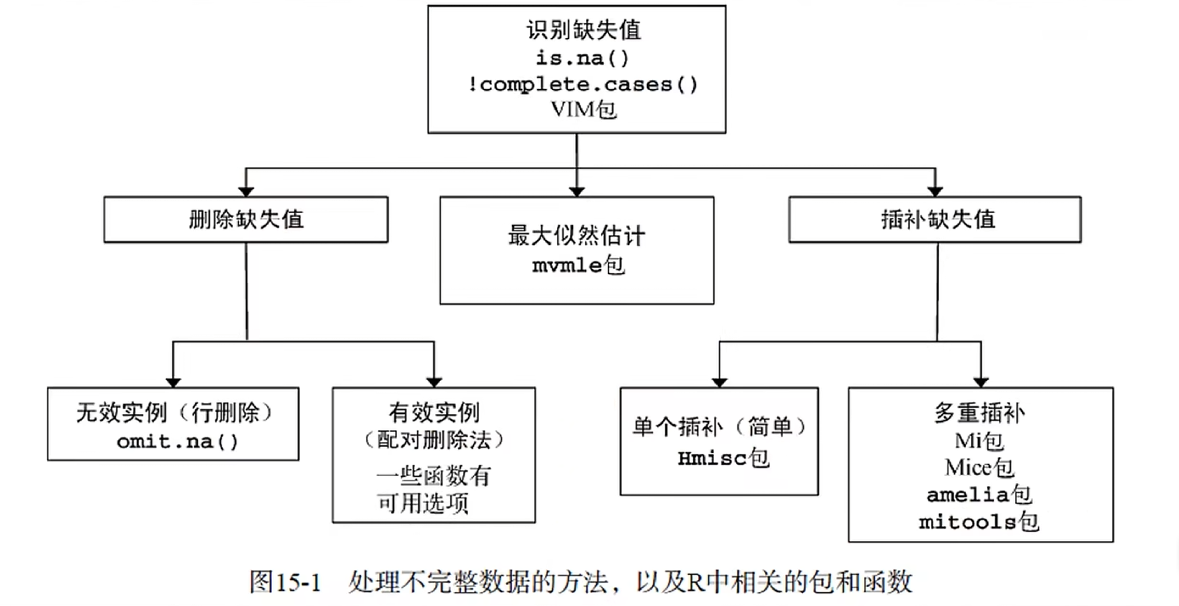
缺失值 在R中,NA代表缺失值,NA是不可用,not available的简称,用来存储缺失信息。
1 2 3 4 5 6 7 8 9 > c <- c(NA, 1 :20 , NA, NA) > c [1 ] NA 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 NA NA > na.omit(c) [1 ] 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 attr(,"na.action" ) [1 ] 1 22 23 attr(,"class" ) [1 ] "omit"
使用na.omit对数据中的缺失值进行删除
不同缺失数据以及它们的不同:
NA是存在的值,但是不知道是多少 NaN是不存在的 Inf存在,分为正无穷Inf和负无穷Inf,表示不可能的值 字符串 1 2 3 4 5 6 7 8 9 10 11 12 > nchar("Hello World" ) [1 ] 11 > length(c("Hello World" , 'c' )) [1 ] 2 > paste("I" ,"love" ,"you" ) [1 ] "I love you" > paste("I" ,"love" ,"you" , sep="-" ) [1 ] "I-love-you" > toupper("two" ) [1 ] "TWO" > tolower("ONE" ) [1 ] "one"
判断语句 if语句 1 2 3 if (boolean_expression) { // 布尔表达式为真将执行的语句 }
if语句语法如上所示。
1 2 3 4 5 6 x <- 50L if (is .integer(x)) { print ("X 是一个整数" ) } [1 ] "X 是一个整数"
if语句实例如上所示。
if…else 语句 1 2 3 4 5 if (boolean_expression) { // 如果布尔表达式为真将执行的语句 } else { // 如果布尔表达式为假将执行的语句 }
if…else…语句语法如上所示。
1 2 3 4 5 6 7 8 9 if (boolean_expression 1 ) { // 如果布尔表达式 boolean_expression 1 为真将执行的语句 } else if ( boolean_expression 2 ) { // 如果布尔表达式 boolean_expression 2 为真将执行的语句 } else if ( boolean_expression 3 ) { // 如果布尔表达式 boolean_expression 3 为真将执行的语句 } else { // 以上所有的布尔表达式都为 false 时执行 }
如果有多个条件判断,可以使用 if…else if…else:
switch语句 1 switch(expression, case1, case2, case3....)
switch语句语法如上所示:
switch语句的语法规则为:
switch语句中的expression是一个常量表达式,可以是整数或字符串,整数返回对应的case位置值,如果整数不在位置范围,返回NULL 若匹配多个值则返回第一个 expression如果是字符串,则对应的是case中变量名对应的值,没有匹配则没有返回值 1 2 3 4 5 6 7 8 9 10 x <- switch( 3 ,"google" ,"runoob" ,"taobao" ,"weibo" ) print (x)[1 ] "taobao"
语法规则1的实例如上:
1 2 3 4 you.like<-"runoob" switch(you.like, google="www.google.com" , runoob = "www.runoob.com" , taobao = "www.taobao.com" ) [1 ] "www.runoob.com"
语法规则2的实例如上:
1 2 3 4 5 6 > x <- switch(4 ,"google" ,"runoob" ,"taobao" ) > x NULL > x <- switch(4 ,"google" ,"runoob" ,"taobao" ) > x NULL
语法规则3的实例如上
循环语句 repeat repeat 循环会一直执行代码,直到条件语句为 true 时才退出循环,退出要使用到 break 语句
1 2 3 4 5 6 repeat { // 相关代码 if (condition) { break } }
repeat语法格式如上:
1 2 3 4 5 6 7 8 9 10 11 12 13 v <- c("Google" ,"Runoob" ) cnt <- 2 while (cnt < 7 ) { print (v) cnt = cnt + 1 } [1 ] "Google" "Runoob" [1 ] "Google" "Runoob" [1 ] "Google" "Runoob" [1 ] "Google" "Runoob"
repeat实例如上:
while 只要给定的条件为 true, while 循环语句会重复执行一个目标语句。这个语句基本上与python一致
1 2 3 4 while (condition){ statement(s); }
语法如上:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 v <- c("Google" ,"Runoob" ) cnt <- 2 while (cnt < 7 ) { print (v) cnt = cnt + 1 } [1 ] "Google" "Runoob" [1 ] "Google" "Runoob" [1 ] "Google" "Runoob" [1 ] "Google" "Runoob" [1 ] "Google" "Runoob"
while循环实例如上:
for for 循环语句可以重复执行指定语句,重复次数可在 for 语句中控制,此语句与python也是比较相似。
1 2 3 for (value in vector) { statements }
for循环的语法如上:
1 2 3 4 5 6 7 8 9 10 v <- LETTERS[1 :4 ] for ( i in v) { print (i) } [1 ] "A" [1 ] "B" [1 ] "C" [1 ] "D"
for循环实例如上:
break 插入在循环体中,用于退出当前循环或语句,并开始脚本执行紧接着的语句,这个与python基本一致
next 跳过当前循环,开始下一次循环,这个类似于python中的continue