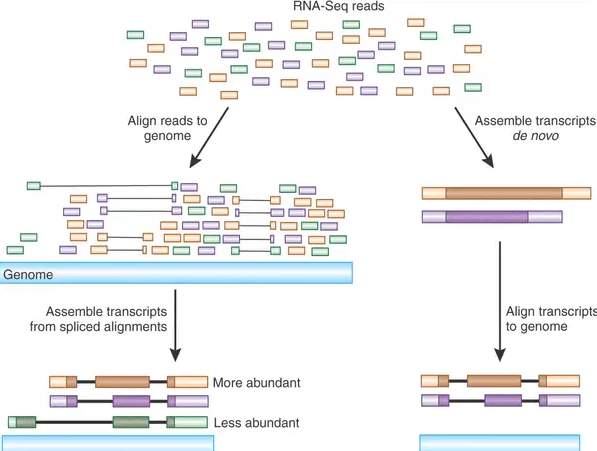
jinhenghao@ubuntu:~/science/25-8-28-RNAseq$ STAR Usage: STAR [options]... --genomeDir /path/to/genome/index/ --readFilesIn R1.fq R2.fq Spliced Transcripts Alignment to a Reference (c) Alexander Dobin, 2009-2022
STAR version=2.7.11b STAR compilation time,server,dir=2025-08-30T05:43:33-07:00 :/home/jinhenghao/science/star/STAR-2.7.11b/source For more details see: <https://github.com/alexdobin/STAR> <https://github.com/alexdobin/STAR/blob/master/doc/STARmanual.pdf>
STAR --runThreadN 8 --runMode genomeGenerate --genomeDir arab_STAR_genome --genomeFastaFiles 00ref/TAIR10_Chr.all.fasta --sjdbGTFfile 00ref/Araport11_GFF3_genes_transposons.201606.gtf --sjdbOverhang 149 STAR version: 2.7.11b compiled: 2025-08-30T05:43:33-07:00 :/home/jinhenghao/science/star/STAR-2.7.11b/source Aug 31 04:12:37 ..... started STAR run Aug 31 04:12:37 ... starting to generate Genome files Aug 31 04:12:38 ..... processing annotations GTF !!!!! WARNING: --genomeSAindexNbases 14 is too large for the genome size=119667750, which may cause seg-fault at the mapping step. Re-run genome generation with recommended --genomeSAindexNbases 12 Aug 31 04:12:40 ... starting to sort Suffix Array. This may take a long time... Aug 31 04:12:40 ... sorting Suffix Array chunks and saving them to disk... Aug 31 04:12:57 ... loading chunks from disk, packing SA... Aug 31 04:12:59 ... finished generating suffix array Aug 31 04:12:59 ... generating Suffix Array index Aug 31 04:13:26 ... completed Suffix Array index Aug 31 04:13:26 ..... inserting junctions into the genome indices Aug 31 04:14:35 ... writing Genome to disk ... Aug 31 04:14:35 ... writing Suffix Array to disk ... Aug 31 04:14:36 ... writing SAindex to disk Aug 31 04:14:38 ..... finished successfully